Leaderboard



Popular Content
Showing content with the highest reputation on 11/18/21 in all areas
-
@tod I totally understand you willing to keep that alpha you found private. Taylor's theorem is the one you are referring to, and the problem is called overfitting. This why those using complex deep-learning algorithms use strategies to dumb the neural network's learnings, so they work out of sample This is also why I am wary of optimization, Monte-Carlo and walk forward analysis, if used to tune up. What I like use optimization for is to find the range of parameters where the strategy works best and worst, not to tune it up, but to understand its limitations. I also like to break it, using it with tickers and timeframes that I know their behavior, to see how the strategy behaves in those situations, as a way to know what to expect, and how to size it. If I can break the strategy easily, I can dismiss it and move on to something else. If it only works with a very specific, single parameter or narrow range, then I dismiss it because it will not work out of sample. It it is hard to break and the parameter range is wide, then we are onto something. For instance, I know that a ticker like GRPN is going to have a massive loss, NVDA or TSLA are going to be rockets, /BTC is going to have massive swings, GLD is going to chop a lot, then make a big move, etc. And I know when the market has flash crashes, continued bear markets, and so on. If I know the drawdown in a very bad scenario, I can size the allocation to that strategy. If I have a strategy that loses very little or even makes some on GRPN, but still makes money on the famous ones and others like For trend momentum strategies, there's a lot written about selecting stocks with a big move history on the leading pack within the leading sector. You will miss an early entry and therefore bragging rights, but you jump in to a confirmed trend that may continue 35% of the time, and when if does, you make enough to compensate the small loses of the other 65% of times the trend died.1 point
-
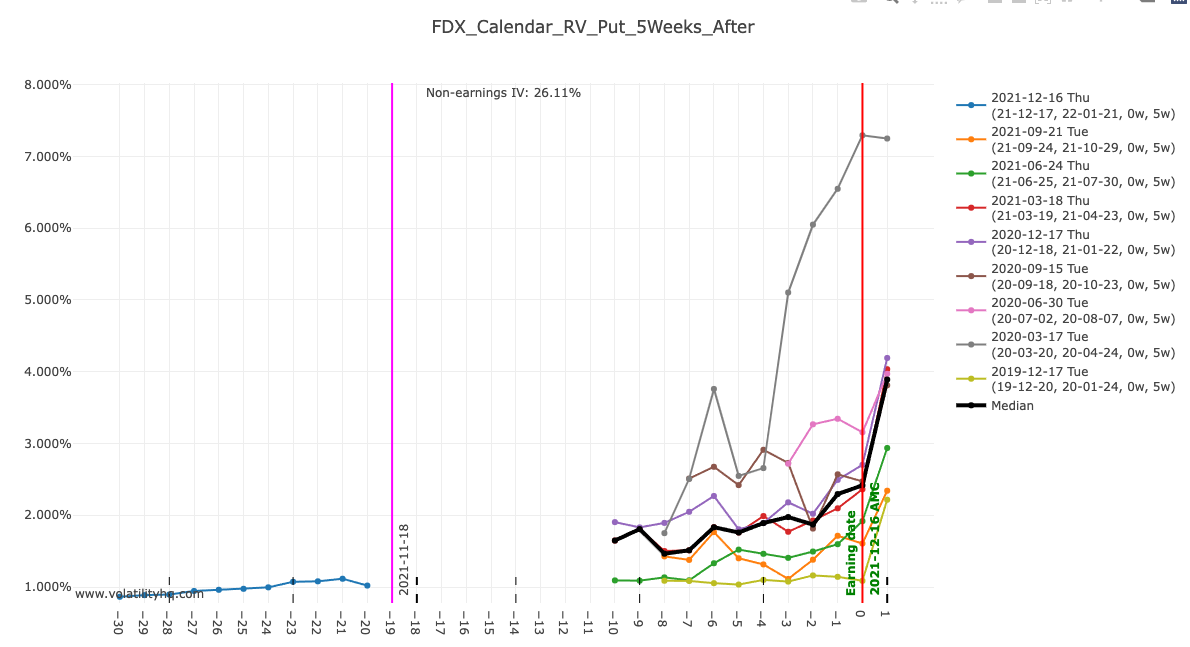
That's because the earning is far away, and there is no median rv at the current T :
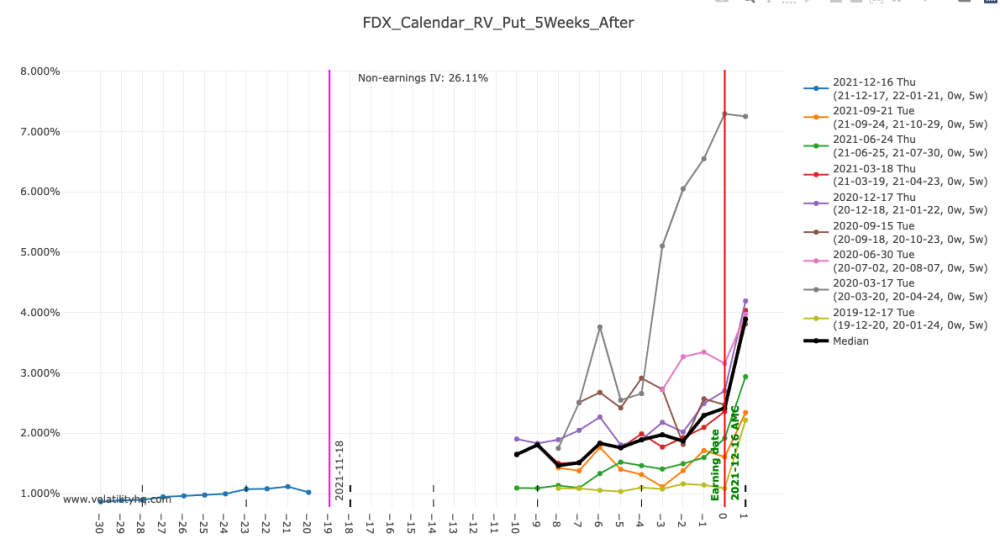 1 point
1 point -
@Bullfighter and @mccoyb53 I came upon the system I mentioned while researching sector rotation strategies. The web is full of references to how sector rotation beats the S&P. The same set of papers are dragged out to support this ad nauseum. One by Mebane Faber always gets a mention (I like Mebane Faber), but there's a dozen others; Asness (I like Asness), etc. I worked for sometime to validate this using the Spyder sector ETFs . I could never show the sector rotation strategy exceeded S&P returns in the long term. Unless they consider occasional returns in excess of 0.1% as outperformance. I could show spurts of outperformance, followed by underperformance, to ultimately end in the same place as simply owning SPY over a 20 year period. But with the code for testing that (I use R), I started playing around with other things. And I stumbled onto a set of parameters in unrelated "financial toolkits" that provided a novel entry and exit trigger; and I built a variant rotation scheme that did outperform SPY in a robust manner. I've found no reference to my happenstance discovery in system strategies, so I'm holding that secret sauce close to the vest for now. I don't mean to be a tease about this. I brought it up to emphasize the best systems are often simple. But finding them can take years and proves devilishly hard. I spent several hundred hours on what now I run with a few dozen lines of code. Most of that for grabbing data, compiling output. The actual 'secret sauce' is less than 50 lines of code. BTW, this system is not scalable beyond a 7 figure account, which may explain why it lives under the radar. My systems building philosophy is strongly influenced by a famous math theorem that states: for any continuous curve (any financial time series will do, drawn as a line chart), there exists a polynomial of finite degree that will match the curve to arbitrary precision. This theorem establishes the downfall of 99% of back testing efforts. A historic timeseries is a fixed, continuous curve. So the theorem above guarantees that with enough indicators and parameter adjustments, you can build a system that matches that time series dot for dot. So most back testing efforts are often futile exercises of crafting the (metaphorical) polynomial that matches the data curve they're testing on. The more indicators you're using, the greater the probability you're just building the equivalent of a curve matching polynomial, which holds true only for that one, fixed time series. As soon as I'm using more than 4 inputs (which is two to many), I get that "uh-oh" feeling. Of course, a complicated system that works on an in-sample set and proves robust on out-of-sample, or on time series from other classes that weren't used to develop the back test, is legitimate. So simple is not a requirement. But the combination of simplicity with robustness is a beautiful thing. I find CMLViz has some properties like that, so I wanted to defend it a bit.1 point



This leaderboard is set to New York/GMT-04:00